
Neocrm Product Vice President / Luo Yi
Introduction
In the previous articles, we explored the vision, scenarios, and pitfalls of AI-native CRM, yet many customers still ran into frustration upon launching their AI pilot projects.
Whether it’s AI generating half-truths due to missing information, falling silent due to disconnected data silos, or being blindly optimistic about sales pipeline opportunities, all these symptoms point to the same reality:
No matter how powerful the model is, it cannot save you from poor data.
By now, the industry has reached a clear consensus: algorithms determine the floor of what AI can do, but data determines its ceiling.
Today, we’re going to uncover the least glamorous, but most critical component of AI implementation – data.

In the AI Era, Data Is No Longer the ‘Structured Forms’ You Think It Is
For the past 20 years, when we talked about data in CRM, we meant structured records: customer name, industry, company size, deal amount, pipeline stage. These were boxes waiting to be filled in.
But in the AI-native era, the definition of data has fundamentally changed. Large models are not fueled merely by cold numbers – they feed on context.
If you look at new emerging CRM SaaS products, they are pioneering new methods where you no longer rely on salespeople to fill in CRM forms. Instead, the system focuses on unstructured data, including:
- Every email exchanged
- Every meeting recording and transcript
- Every instant interaction in customer chat groups
- Every clause inside a quotation PDF
Traditional CRM is a recorder of outcomes, while AI needs to be a re-constructor of processes.
If your CRM contains only results, AI can only help you generate reports. Only when your CRM captures the process can AI analyze, predict, and recommend strategies.
This is the fundamental reason many AI initiatives fail: Companies try to feed AI with the same structured data originally designed for BI – resulting in severe ‘malnutrition’.
The Three Barriers Blocking AI
From our experience engaging in customer projects, what prevents AI from delivering value is usually not a lack of data, but the wrong state of the data.
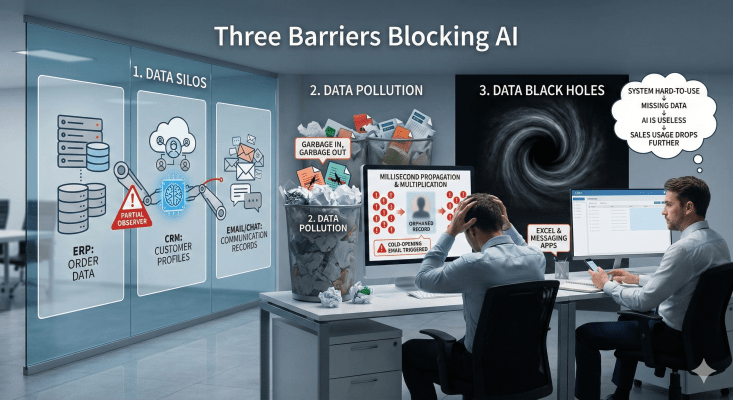
1. Data Silos: AI is missing the forest for the trees
In many enterprises, data is fragmented:
- ERP holds order data
- CRM holds customer profiles
- Email/Chat holds communication records
- Cloud storage holds tender documents
When a salesperson asks AI, “Is this customer worth following up?”
- If AI sees only CRM, it says: “Yes, it’s a big account.”
- If AI also sees ERP, it might say: “Not recommended as last year’s payment was 180 days overdue and credit rating is negative”
If enterprises fail to break down system walls, AI will forever remain a partial observer, giving advice that is not only useless, but potentially harmful.
2. Data Pollution: Garbage In, Garbage Out but Amplified
In the traditional software era, data errors required manual verification. In the AI era, errors propagate in milliseconds and multiply.
In CRM, you may have:
- ‘Customer A (Group)’ as an active enterprise account
- Meanwhile, old un-linked records still exist – ‘Customer A Malaysia Subsidiary’, ‘Customer A R&D Center’, etc.
When AI detects a new tender announcement from this client, instead of matching it to the key account director actively managing the group, it mistakenly links it to the orphaned ‘Customer A Malaysia Subsidiary’ record.
The system immediately triggers an Agent, automatically generating a cold-opening email and recommends immediate contact, while assigning it to a telesales responsible for unowned accounts.
The telesales reaches out to a senior executive at the customer, all while your key account director is in the middle of a critical contract negotiation.
The competitor hears about it and tells the client: “How can you trust them with your project when they can’t even use the system correctly themselves?”
3. Data Black Holes: Hard-to-Use is as good as No Data
Because CRM experiences were poor in the past, salespeople avoided using them. Real business happened and is captured outside the system, in Excel files and personal messaging apps.
What remained in the system were ‘fake’ data entered purely to pass inspections.
Inevitably, AI trained on such data ends up presenting inaccurate data and giving useless suggestions, perpetuating the vicious cycle:
System hard-to-use → Missing data → AI is useless → Sales usage drops further
Breaking Through: From Data-Entry to Data-Capture
Faced with these hard truths, should companies stop and spend three years on data governance? Of course not.
The 2026 solution is not to make people adapt to data, but to use technology to capture data. This is the core revolution of AI-native CRM – transforming data entry into data capture.
1. Automation Is the First Productivity Engine
Stop expecting salespeople to spend one hour every day to update CRM.
A qualified AI CRM should behave like an invisible assistant:
- Omni-channel integration: automatically sync meetings, emails, calendars, and conversations
- Intelligent parsing: Scan a business card → OCR creates a contact Receive an inquiry email → AI generates an opportunity record
Only when data creation no longer relies solely on human discipline, can complete and accurate records be guaranteed.
2. Let AI Be the Monitor of Data Governance
In traditional CRM, data maintenance and cleaning relied heavily on manual comparisons. This is exactly what AI excels at.
Let AI run silently in the background performing:
- Automatic de-duplication: “Detected ‘Shangri-la Group’ and ‘Shangrila Hotel’ as highly likely the same customer – merge recommended.”
- Automatic enrichment: “Detected missing industry tag. Based on their official website, auto-filled as Internet / Software.”
Using AI to repair the data foundation is a critical step towards a positive feedback loop.
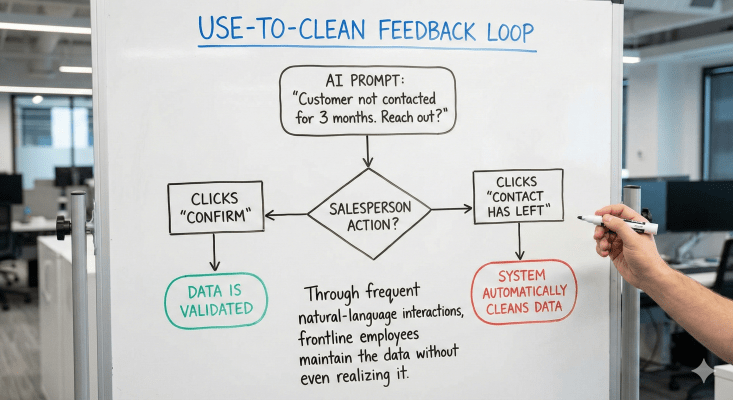
3. Build a ‘Use-to-Clean’ Feedback Loop
The best data governance happens within business workflows.
When AI prompts: “This customer hasn’t been contacted for three months. Would you like to proactively reach out?”
- If the salesperson clicks Confirm, the data is validated.
- If they click Contact has left, the system automatically cleans the data.
Through frequent natural-language interactions, frontline employees maintain the data without even realizing it.
Advanced Stage: Building AI’s Interpreter – The Semantic Layer
If data-capture solves whether data exists, the semantic layer solves whether data is understood. This is the most easily overlooked, but the most significant roadblock in deep AI adoption.
After reviewing numerous failed cases, we reached a brutal conclusion:
99% of AI Agent failures are not because the model isn’t smart enough, but because it doesn’t know which data to use, or misunderstands its meaning.
1. Why Does AI Misuse Data?
Databases are built for programs, not for AI.
At the CRM database level, there might be a field such as ‘status_code = 3’.
- To sales, it means ‘customer verified’
- To finance, it means ‘credit approved’
So when you ask AI: “Find all qualified customers,” without an interpretation layer, AI can only guess based on field names.
The result? Marketing Agents, Sales Agents, and Service Agents each produce a different list of qualified customers.
This is the consequence of a missing semantic layer. Each Agent requires complex, duplicated prompts, with high development cost and conflicting outputs.
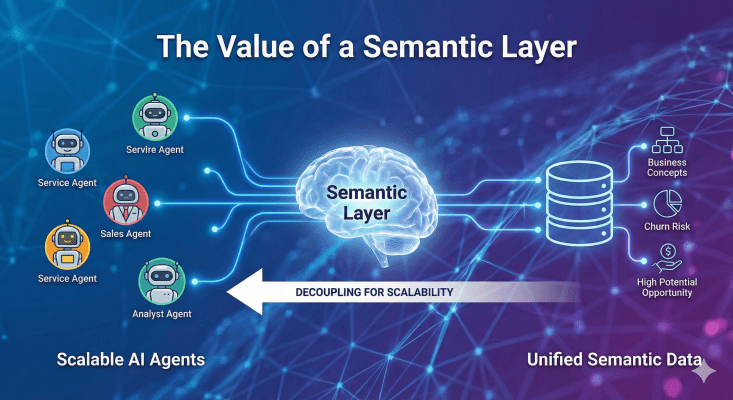
2. What Is a Semantic Layer?
The semantic layer is the official ‘translator’ between:
- the obscure database
- and the intelligent Agent
It translates cold data into unified, reason-ready business language.
In AI CRM architecture, the semantic layer is an essential part of the design, having:
- Unified definitions Define ‘high potential opportunity’ centrally (for example, interaction frequency > 3 times a week AND decision-maker is involved actively)
- Abstracted complexity Agents don’t need to know which table stores data or how tables join. They simply issue instructions to the semantic layer, which translates them into precise queries.
3. The Value: Turning Agents from One-Off Toys into a Scalable Army
The biggest value of a semantic layer is decoupling:
- Eliminates ‘hallucination’: AI no longer guesses field meanings but uses validated business concepts
- Capability re-use: When a domain specific term ‘churn risk’ is defined, Service Agents, Sales Agents, and Analyst Agents can all reuse it
- Agility: When business logic changes, update the semantic layer once and every Agent updates automatically
AI’s scalability does not depend on the Agent itself, but on whether it is built on unified, reason-based semantic data.
Final Thoughts: No Data Strategy = No AI Strategy
Customers often ask me: “Our data foundation is very poor, are we even suitable for AI?”
My answer is usually: “Precisely because your data foundation is weak, you need AI even more, but you must change your starting point.”
Don’t start by asking AI to make complex strategic decisions. Start by letting AI capture and clean data.
Let AI help you rebuild the foundation, slowly picking up unstructured data scattered across chats, emails, and documents, and turning it into enterprise digital assets.
The global SaaS industry is shifting from Software-as-a-Service to Service-as-Software. In this transformation, data is no longer static inventory, it is constantly flowing fuel source.
Once we’ve solved cognition (Article 1), identified the right scenarios (Articles 2 & 3), and begun reinforcing the data foundation (this article), we can finally start to look ahead into 2026 and beyond.
In the final article of this series, I will make some bold predictions and trade-offs:
When AI becomes standard, where will CRM ultimately go? Where should enterprises spend their 2026 budgets most wisely?


